
Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss

Large language models are getting incredibly powerful, but let’s be honest—their inference speed is still a massive headache for anyone trying to use them in production. Google just launched Multi-Token Prediction (MTP) drafters for the Gemma 4 model family. This specialized speculative decoding architecture can actually triple (3x) your speed at inference time, all without sacrificing a bit of output quality or reasoning accuracy. The release comes just weeks after Gemma 4 surpassed 60 million downloads and directly targets one of the most persistent pain points in deploying large language models: the memory-bandwidth bottleneck that slows token generation regardless of hardware capability.
Why LLM Inference is Slow?
Today’s large language models operate autoregressively. They produce exactly one token at a time, sequentially. Every single token generation requires loading billions of model parameters from VRAM (video RAM) into compute units. This process is described as memory-bandwidth bound. The bottleneck is not the raw computing power of the GPU or processor, but the speed at which data can be transferred from memory to the compute units.
The consequence is a significant latency bottleneck: compute sits underutilized while the system is busy just moving data around. What makes this especially inefficient is that the model applies the same amount of computation to a trivially predictable token like predicting “words” after “Actions speak louder than…” as it does to generating a complex logical inference. There’s no mechanism in standard autoregressive decoding to exploit how easy or hard the next token is to predict.
What is Speculative Decoding?
Speculative decoding is the foundational technique that Gemma 4’s MTP drafters are built on. The technique decouples token generation from verification by pairing two models: a lightweight drafter and a heavy target model.

Here’s how the pipeline works in practice. The small, fast drafter model proposes several future tokens in rapid succession — a “draft” sequence — in less time than the large target model (e.g., Gemma 4 31B) takes to process even a single token. The target model then verifies all of these suggested tokens in parallel in a single forward pass. If the target model agrees with the draft, it accepts the entire sequence — and even generates one additional token of its own in the process. This means an application can output the full drafted sequence plus one extra token in roughly the same wall-clock time it would normally take to generate just one token.
Since the primary Gemma 4 model retains the final verification step, the output is identical to what the target model would have produced on its own, token-by-token. There is no quality tradeoff — it is a lossless speedup.
MTP: What’s New in the Gemma 4 Drafter Architecture
Google has introduced several architectural enhancements that make the Gemma 4 MTP drafters particularly efficient. The draft models seamlessly utilize the target model’s activations and share its KV cache (key-value cache). The KV cache is a standard optimization in transformer inference that stores intermediate attention computations so they don’t need to be recalculated on every step. By sharing this cache, the drafter avoids wasting time recomputing context that the larger target model has already processed.
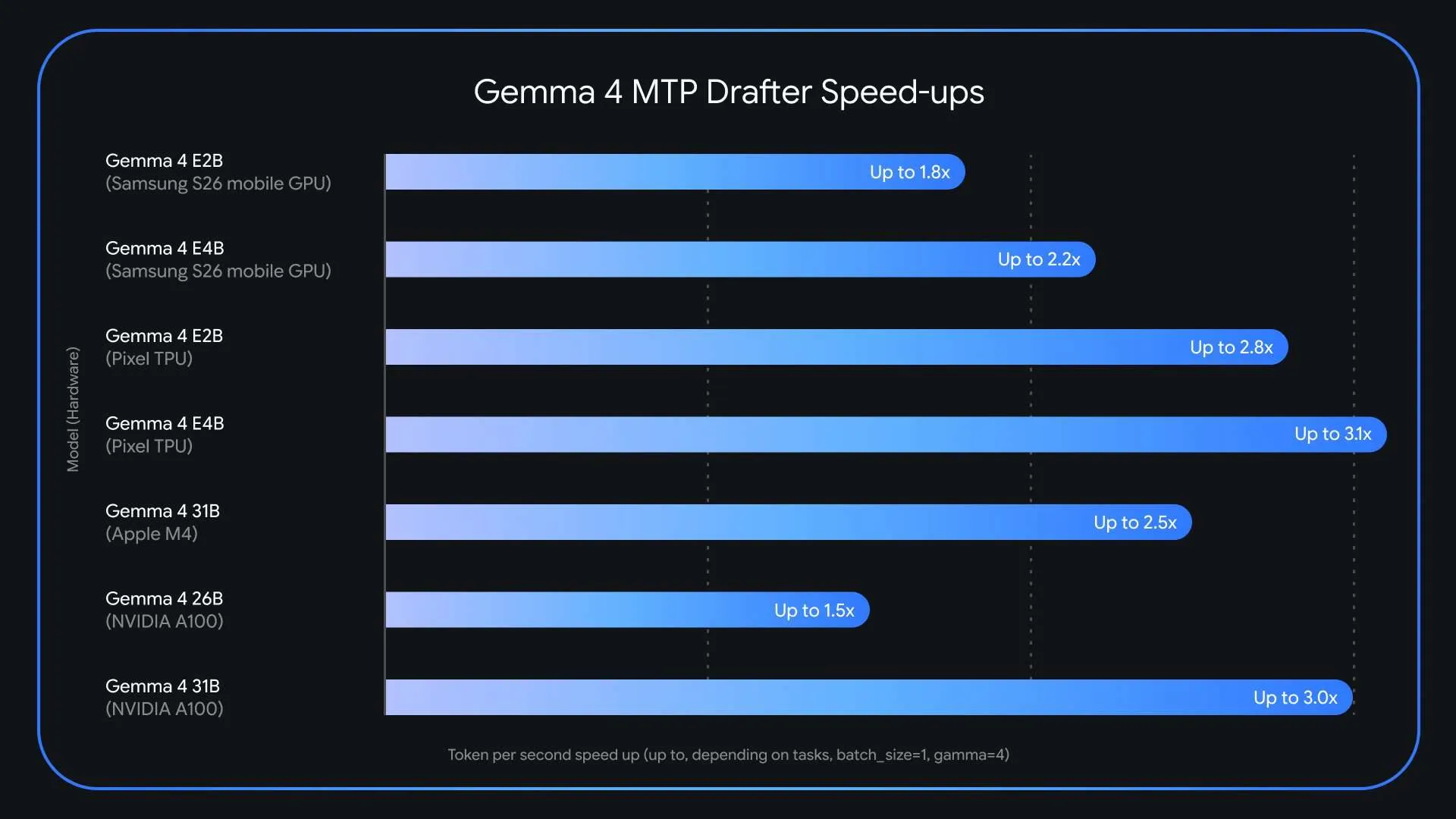
Additionally, for the E2B and E4B edge models, the smallest Gemma 4 variants designed to run on mobile and edge devices — Google implemented an efficient clustering technique in the embedder layer. This specifically addresses a bottleneck prominent on edge hardware: the final logit calculation, which maps internal model representations to vocabulary probabilities. The clustering approach accelerates this step, improving end-to-end generation speed on hardware-constrained devices.
For hardware-specific performance, the Gemma 4 26B mixture-of-experts (MoE) model presents unique routing challenges on Apple Silicon at a batch size of 1. However, increasing the batch size to between 4 and 8 unlocks up to a ~2.2x speedup locally. Similar batch-size-dependent gains are observed on NVIDIA A100 hardware.
Key Takeaways
Google has released Multi-Token Prediction (MTP) drafters for the Gemma 4 model family, delivering up to 3x faster inference speeds without any degradation in output quality or reasoning accuracy.
MTP drafters use a speculative decoding architecture that pairs a lightweight drafter model with a heavy target model — the drafter proposes several tokens at once, and the target model verifies them all in a single forward pass, breaking the one-token-at-a-time bottleneck.
The draft models share the target model’s KV cache and activations, and for E2B and E4B edge models, an efficient clustering technique in the embedder addresses the final logit calculation bottleneck — enabling faster generation even on memory-constrained devices.
MTP drafters are available now under the Apache 2.0 license, with model weights on Hugging Face and Kaggle.
Check out the Model Weights and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us










