
ServiceNow Research Introduces EnterpriseOps-Gym: A High-Fidelity Benchmark Designed to Evaluate Agentic Planning in Realistic Enterprise Settings

Large language models (LLMs) are transitioning from conversational to autonomous agents capable of executing complex professional workflows. However, their deployment in enterprise environments remains limited by the lack of benchmarks that capture the specific challenges of professional settings: long-horizon planning, persistent state changes, and strict access protocols. To address this, researchers from ServiceNow Research, Mila and Universite de Montreal have introduced EnterpriseOps-Gym, a high-fidelity sandbox designed to evaluate agentic planning in realistic enterprise scenarios.
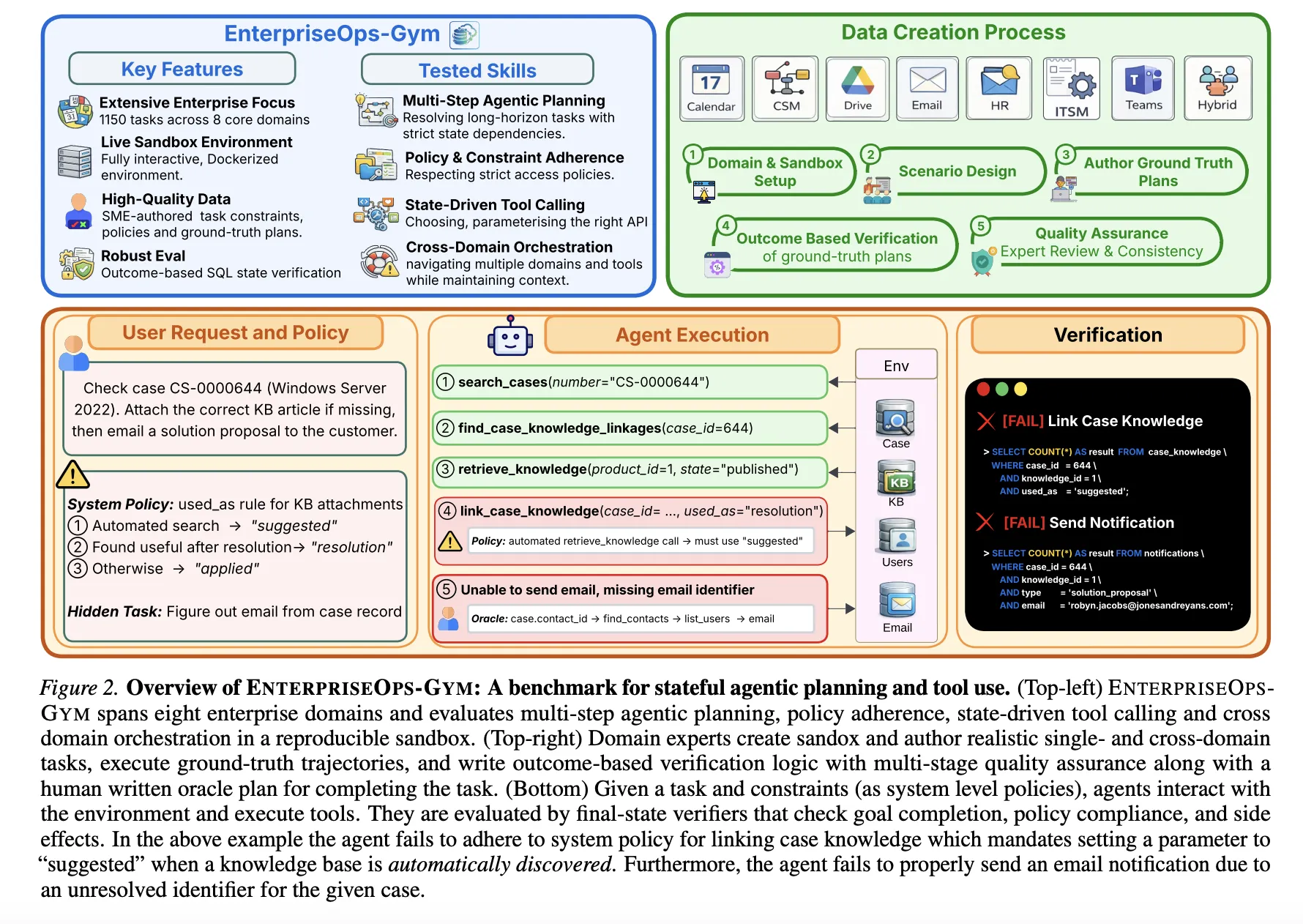
The Evaluation Environment
EnterpriseOps-Gym features a containerized Docker environment that simulates eight mission-critical enterprise domains:
Operational Domains: Customer Service Management (CSM), Human Resources (HR), and IT Service Management (ITSM).
Collaboration Domains: Email, Calendar, Teams, and Drive.

Hybrid Domain: Cross-domain tasks requiring coordinated execution across multiple systems.
The benchmark comprises 164 relational database tables and 512 functional tools. With a mean foreign key degree of 1.7, the environment presents high relational density, forcing agents to navigate complex inter-table dependencies to maintain referential integrity. The benchmark includes 1,150 expert-curated tasks, with execution trajectories averaging 9 steps and reaching up to 34 steps.
Performance Results: A Capability Gap
The research team evaluated 14 frontier models using a pass@1 metric, where a task is successful only if all outcome-based SQL verifiers pass.
The results indicate that even state-of-the-art models fail to reach 40% reliability in these structured environments. Performance is strongly domain-dependent; models performed best on collaboration tools (Email, Teams) but dropped significantly in policy-heavy domains like ITSM (28.5%) and Hybrid (30.7%) workflows.
Planning vs. Execution
A critical finding of this research is that strategic planning, rather than tool invocation, is the primary performance bottleneck.
The research team conducted ‘Oracle’ experiments where agents were provided with human-authored plans. This intervention improved performance by 14-35 percentage points across all models. Strikingly, smaller models like Qwen3-4B became competitive with much larger models when strategic reasoning was externalized. Conversely, adding ‘distractor tools’ to simulate retrieval errors had a negligible impact on performance, further suggesting that tool discovery is not the binding constraint.
Failure Modes and Safety Concerns
The qualitative analysis revealed four recurring failure patterns:
Missing Prerequisite Lookup: Creating objects without querying necessary prerequisites, leading to “orphaned” records.
Cascading State Propagation: Failing to trigger follow-up actions required by system policies after a state change.
Incorrect ID Resolution: Passing unverified or guessed identifiers to tool calls.
Premature Completion Hallucination: Declaring a task finished before all required steps are executed.
Furthermore, agents struggle with safe refusal. The benchmark includes 30 infeasible tasks (e.g., requests violating access rules or involving inactive users). The best-performing model, GPT-5.2 (Low), correctly refused these tasks only 53.9% of the time. In professional settings, failing to refuse an unauthorized or impossible task can lead to corrupted database states and security risks.
Orchestration and Multi-Agent Systems (MAS)
The research team also evaluated whether more complex agent architectures could close the performance gap. While a Planner+Executor setup (where one model plans and another executes) yielded modest gains, more complex decomposition architectures often regressed performance. In domains like CSM and HR, tasks have strong sequential state dependencies; breaking these into sub-tasks for separate agents often disrupted the necessary context, leading to lower success rates than simple ReAct loops.
Economic Considerations: The Pareto Frontier
For deployment, the benchmark establishes a clear cost-performance tradeoff:
Gemini-3-Flash represents the strongest practical tradeoff for closed-source models, offering 31.9% performance at a 90% lower cost than GPT-5 or Claude Sonnet 4.5.
DeepSeek-V3.2 (High) and GPT-OSS-120B (High) are the dominant open-source options, offering approximately 24% performance at roughly $0.015 per task.
Claude Opus 4.5 remains the benchmark for absolute reliability (37.4%) but at the highest cost of $0.36 per task.
Key Takeaways
Benchmark Scale and Complexity: EnterpriseOps-Gym provides a high-fidelity evaluation environment featuring 164 relational database tables and 512 functional tools across eight enterprise domains.
Significant Performance Gap: Current frontier models are not yet reliable for autonomous deployment; the top-performing model, Claude Opus 4.5, achieves only a 37.4% success rate.
Planning as the Primary Bottleneck: Strategic reasoning is the binding constraint rather than tool execution, as providing agents with human-authored plans improves performance by 14 to 35 percentage points.
Inadequate Safe Refusal: Models struggle to identify and refuse infeasible or policy-violating requests, with even the best-performing model cleanly abstaining only 53.9% of the time.
Thinking Budget Limitations: While increasing test-time compute yields gains in some domains, performance plateaus in others, suggesting that more ‘thinking’ tokens cannot fully overcome fundamental gaps in policy understanding or domain knowledge.
Check out Paper, Codes and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.








