
DeepSeek-AI Just Released DeepSeek-V3: A Strong Mixture-of-Experts (MoE) Language Model with 671B Total Parameters with 37B Activated for Each Token
The field of Natural Language Processing (NLP) has made significant strides with the development of large-scale language models (LLMs). However, this progress has brought its own set of challenges. Training and inference require substantial computational resources, the availability of diverse, high-quality datasets is critical, and achieving balanced utilization in Mixture-of-Experts (MoE) architectures remains complex. These factors contribute to inefficiencies and increased costs, posing obstacles to scaling open-source models to match proprietary counterparts. Moreover, ensuring robustness and stability during training is an ongoing issue, as even minor instabilities can disrupt performance and necessitate costly interventions.
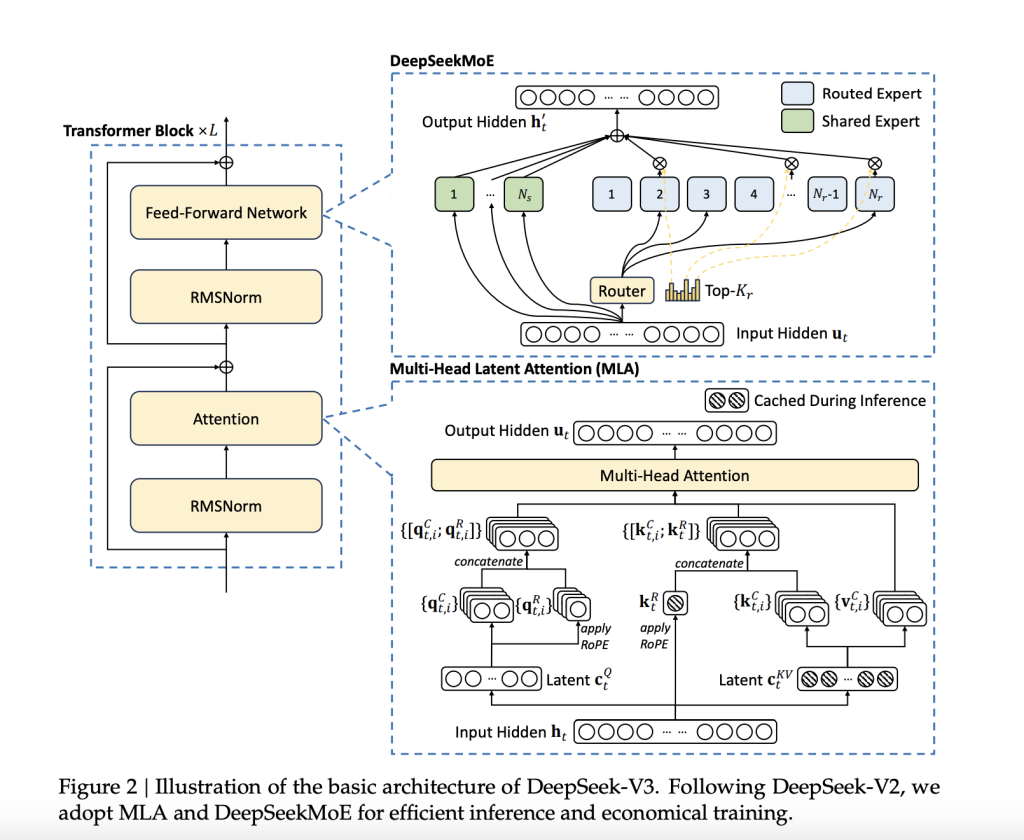
DeepSeek-AI just gave a Christmas present to the AI world by releasing DeepSeek-V3, a Mixture-of-Experts (MoE) language model featuring 671 billion parameters, with 37 billion activated per token. The model builds on proven architectures such as Multi-Head Latent Attention (MLA) and DeepSeekMoE, which were refined in earlier versions. DeepSeek-V3 has been trained on an extensive dataset of 14.8 trillion high-quality tokens, ensuring a broad and diverse knowledge base. Importantly, the model is fully open-source, with accessible models, papers, and training frameworks for the research community to explore.
Technical Details and Benefits
DeepSeek-V3 incorporates several innovations aimed at addressing long-standing challenges in the field. Its auxiliary-loss-free load balancing strategy ensures efficient distribution of computational loads across experts while maintaining model performance. The adoption of a multi-token prediction training objective enhances data efficiency and facilitates faster inference through speculative decoding. Additionally, FP8 mixed precision training improves computational efficiency by reducing GPU memory usage without sacrificing accuracy. The DualPipe algorithm further minimizes pipeline bubbles by overlapping computation and communication phases, reducing all-to-all communication overhead. These advancements enable DeepSeek-V3 to process 60 tokens per second during inference—a significant improvement over its predecessor.
Performance Insights and Results
DeepSeek-V3 has been rigorously evaluated across multiple benchmarks, demonstrating strong performance. On educational datasets like MMLU and MMLU-Pro, it achieved scores of 88.5 and 75.9, respectively, outperforming other open-source models. In mathematical reasoning tasks, it set new standards with a score of 90.2 on MATH-500. The model also performed exceptionally in coding benchmarks such as LiveCodeBench. Despite these achievements, the training cost was kept relatively low at $5.576 million, requiring only 2.788 million H800 GPU hours. These results highlight DeepSeek-V3’s efficiency and its potential to make high-performance LLMs more accessible.



Conclusion
DeepSeek-V3 represents a meaningful advancement in open-source NLP research. By tackling the computational and architectural challenges associated with large-scale language models, it establishes a new benchmark for efficiency and performance. Its innovative training methods, scalable architecture, and strong evaluation results make it a competitive alternative to proprietary models. DeepSeek-AI’s commitment to open-source development ensures that the broader research community can benefit from its advancements.
Check out the Paper, GitHub Page, and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









