
Is America falling behind in the AI race?
Several major US artificial intelligence companies have expressed fear around an erosion of America’s edge in AI development. In recent...

Several major US artificial intelligence companies have expressed fear around an erosion of America’s edge in AI development. In recent...
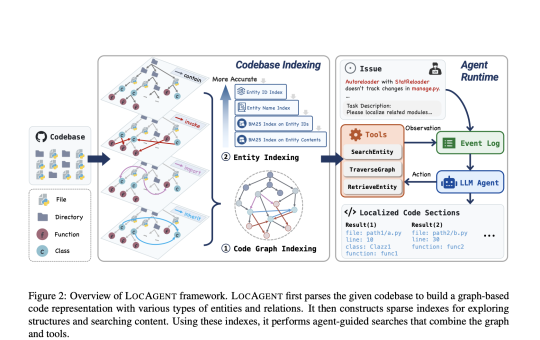
Software maintenance is an integral part of the software development lifecycle, where developers frequently revisit existing codebases to fix bugs,...

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More As...

Anthropic has announced its AI assistant Claude can now search the web, providing users with more up-to-date and relevant responses....

In this tutorial, we explore an innovative and practical application of IBM’s open-source ResNet-50 deep learning model, showcasing its capability...

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More A...

Have you ever stared at a blank AI chat window, not knowing how to ask for what you want? You’re...
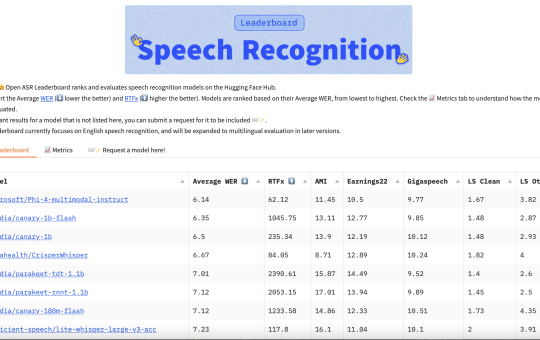
In the realm of artificial intelligence, multilingual speech recognition and translation have become essential tools for facilitating global communication. However,...

Shawn Pierre, the chairperson of the Independent Games Festival, opened the Independent Games Festival Awards with a plea to support...

NVIDIA has launched Dynamo, an open-source inference software designed to accelerate and scale reasoning models within AI factories. Efficiently managing...

Every day, organizations face complex logistical challenges—from optimizing delivery routes and managing supply chains to streamlining production schedules. These tasks...
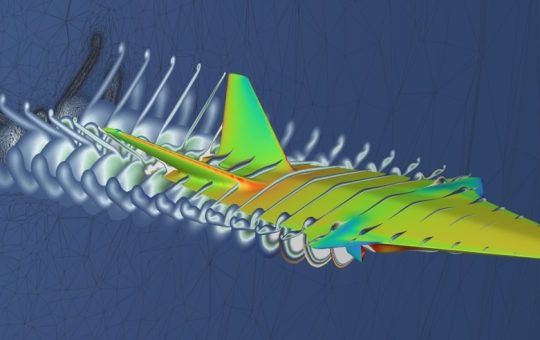
Rune Aero has revolutionized its aircraft development process using an interactive virtual wind tunnel powered by Physics AI, achieving an...

As Saudi Arabia accelerates its journey toward becoming a global leader in digital innovation, the Smart Data & AI Summit...
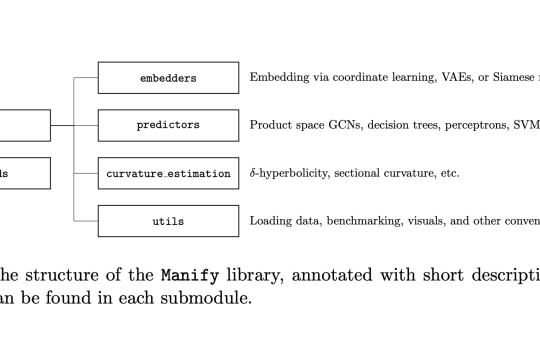
Machine learning has expanded beyond traditional Euclidean spaces in recent years, exploring representations in more complex geometric structures. Non-Euclidean representation...

Veterans have had help from the Department of Veterans Affairs adjusting to work-life challenges for years. But employees at the department’s...

Manus AI agent is China’s latest artificial intelligence breakthrough that’s turning heads in Silicon Valley and beyond. Manus was launched...
In this tutorial, we demonstrate how to build an AI-powered PDF interaction system in Google Colab using Gemini Flash 1.5,...

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More Businesses...

OpenAI and Google are each urging the US government to take decisive action to secure the nation’s AI leadership. “As...
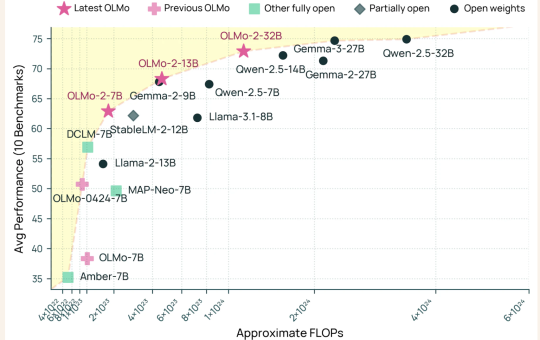
The rapid evolution of artificial intelligence (AI) has ushered in a new era of large language models (LLMs) capable of...
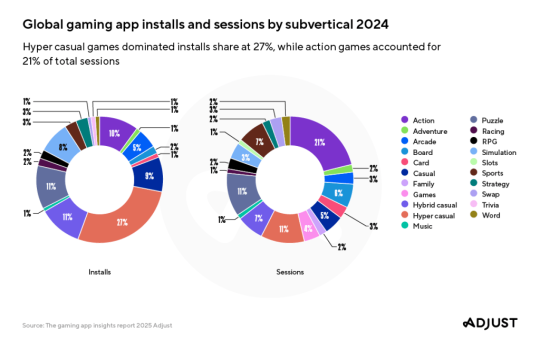
The mobile gaming market shows positive signs of life in early 2025, according to the latest report from analytics company...

ServiceNow has launched its Yokohama platform which introduces AI agents across various sectors to boost workflows and maximise end-to-end business...



