
NVIDIA AI Introduces MM-Embed: The First Multimodal Retriever Achieving SOTA Results on the Multimodal M-BEIR Benchmark
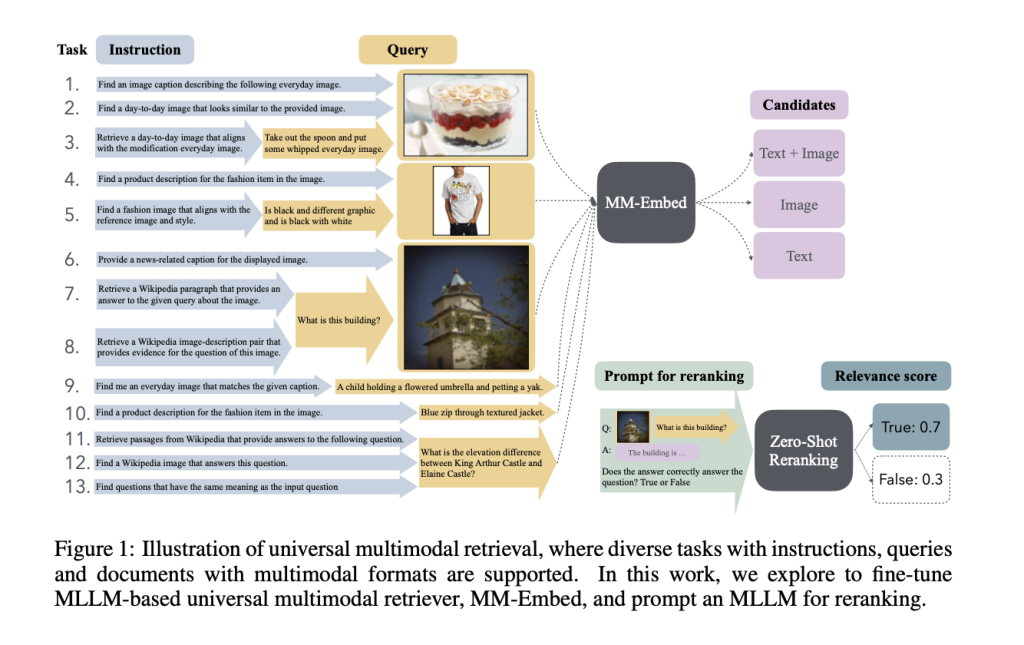
In the world of information retrieval, one of the most challenging tasks is to create a system that can seamlessly understand and retrieve relevant content across different formats, such as text and images, without losing accuracy. Most state-of-the-art retrieval models are still confined to a single modality—either text-to-text or image-to-image retrieval—which limits their applicability in real-world scenarios where information comes in diverse formats. This limitation is particularly evident in complex applications, such as visual question answering or fashion image retrieval, where both text and images are needed to derive relevant answers. Therefore, the need for a universal multimodal retriever that can handle text, images, and their combinations effectively has never been greater. The key challenges include the inherent difficulty of cross-modal understanding and overcoming biases within individual modalities.
NVIDIA researchers have stepped up to address these challenges by introducing MM-Embed, the first multimodal retriever that has achieved state-of-the-art (SOTA) results on the multimodal M-BEIR benchmark and ranks among the top five retrievers on the text-only MTEB retrieval benchmark. MM-Embed aims to bridge the gap between multiple retrieval formats, allowing for a more fluid search experience that spans both text and image-based content. The researchers fine-tuned MM-Embed using a multimodal large language model (MLLM) as a bi-encoder retriever across 16 retrieval tasks and ten datasets, demonstrating its versatility. Unlike other existing retrievers, MM-Embed does not restrict itself to a single type of data but instead supports complex user queries that may be composed of both text and images. Furthermore, the introduction of modality-aware hard negative mining plays a crucial role in enhancing MM-Embed’s retrieval quality by minimizing the biases commonly seen in MLLMs.

The technical implementation of MM-Embed involved a series of key strategies designed to maximize retrieval performance. The model uses a bi-encoder architecture to fine-tune the retrieval process, leveraging modality-aware hard negative mining to mitigate biases that arise when handling mixed-modality data. In simple terms, this mining approach helps the model focus more accurately on the target modality—whether text, image, or a combination—thus improving its ability to handle difficult, interleaved text-image queries. Additionally, MM-Embed undergoes continual fine-tuning to boost its text retrieval capabilities without sacrificing its strength in multimodal tasks. This makes it particularly effective in a diverse set of scenarios, from retrieving Wikipedia paragraphs in response to a text-based query about an image to finding similar images based on complex descriptions.
This advancement is significant for several reasons. First, MM-Embed sets a new benchmark for multimodal retrieval with an average retrieval accuracy of 52.7% across all M-BEIR tasks, surpassing previous state-of-the-art models. When it comes to specific domains, MM-Embed showed notable improvements, such as a retrieval accuracy (R@5) of 73.8% for the MSCOCO dataset, indicating its strong ability to understand complex image captions. Moreover, by employing zero-shot reranking using multimodal LLMs, MM-Embed further enhanced retrieval precision in cases involving intricate text-image queries, such as visual question answering and composed image retrieval tasks. Notably, MM-Embed improved ranking accuracy in CIRCO’s composed image retrieval task by more than 7 points, showcasing the efficacy of prompting LLMs for reranking in challenging, real-world scenarios.

In conclusion, MM-Embed represents a major leap forward in multimodal retrieval. By effectively integrating and enhancing both text and image retrieval capabilities, it paves the way for more versatile and sophisticated search engines capable of handling the varied ways people seek information in today’s digital landscape.
Check out the Paper and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









