
Balancing Act: The Impact of Format Restrictions on Reasoning in Large Language Models
As LLMs have become increasingly capable of performing various tasks through few-shot learning and instruction following, their inconsistent output formats have hindered their reliability and usability in industrial contexts. This inconsistency complicates the extraction and evaluation of generated content, particularly when structured generation methods, such as JSON and XML, are employed. The authors investigate whether imposing format restrictions on LLMs negatively impacts their reasoning abilities and overall performance, particularly in tasks requiring domain knowledge and comprehension.
Current methods for structured generation include constrained decoding, format-restricting instructions (FRI), and natural language to format (NL-to-Format) approaches. Constrained decoding, often implemented in JSON mode, limits the output space of LLMs to ensure valid structured data, which is essential for many industrial applications. Format-restricting instructions direct LLMs to generate responses in specified formats, such as requiring a response to be in a specific order or to follow a particular structure. The NL-to-Format method first allows LLMs to respond in natural language before converting the output to the desired format. The authors propose a systematic investigation into these methodologies, assessing their impact on LLM performance across various tasks, including reasoning and classification.
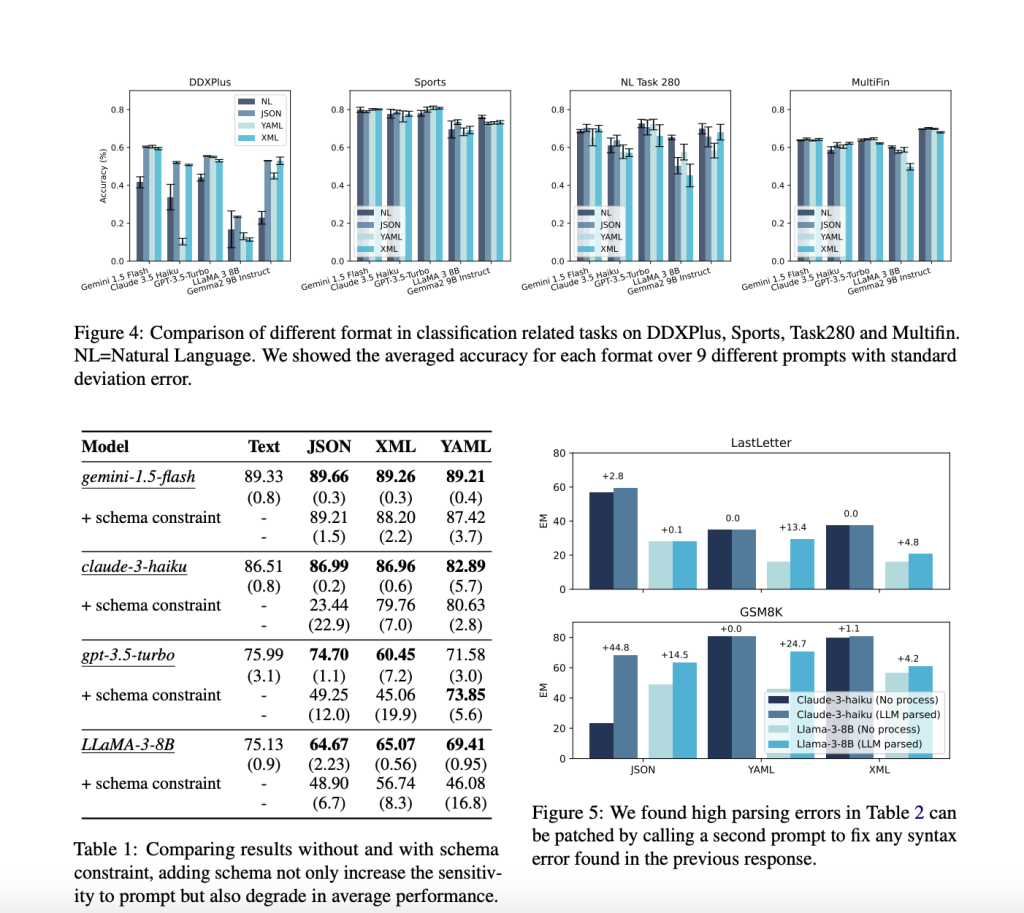
The proposed methodology from Appier AI Research and National Taiwan University involves extensive empirical experiments to evaluate the effects of format restrictions on LLM performance. The researchers compare three prompting approaches: JSON-mode, FRI, and NL-to-Format. Their findings reveal that stricter format constraints, such as those imposed by JSON mode, lead to significant declines in reasoning abilities. For instance, in reasoning tasks like GSM8K and Last Letter Concatenation, the performance of LLMs is notably worse under strict format constraints compared to more relaxed approaches. The authors also highlight that the order of keys in structured outputs and the separation of reasoning from format adherence play crucial roles in maintaining LLM capabilities while providing structured responses.
In terms of performance, the study presents compelling evidence that format restrictions can significantly affect LLM outputs. For reasoning tasks, the JSON-mode approach often results in lower accuracy due to its rigid structure, which may disrupt the model’s reasoning process. In contrast, the NL-to-Format method performs comparable to unrestricted natural language responses, suggesting that allowing LLMs to generate content freely before formatting can preserve their reasoning capabilities. Interestingly, the results differ for classification tasks, where JSON mode sometimes enhances performance by constraining the answer space, thereby reducing errors in answer selection. This task-dependent variability underscores the need for careful consideration when implementing format restrictions in LLM applications, urging the audience to be cautious and mindful in their approach.

One of the standout features of the proposed method is its ability to scale effectively. Unlike traditional models that may falter when applied to extensive datasets, this approach maintains its efficiency and accuracy regardless of the dataset size. The researchers conducted a series of rigorous tests to evaluate the performance of their method, comparing it against existing tools. The results demonstrated a significant improvement in both speed and accuracy, with the proposed method outperforming traditional techniques across various metrics. This enhanced performance is attributed to the innovative design of the neural network and the meticulous optimization of the analytical processes, providing a reliable solution for data analysis. The meticulous optimization of the analytical processes should instill confidence in the reliability of the proposed method among researchers and professionals.
In summary, the research paper provides a comprehensive overview of the challenges associated with text and data analysis and presents a groundbreaking solution that addresses these issues. The proposed method, with its advanced deep learning architecture and optimized analytical processes, not only offers a promising alternative to traditional tools but also has the potential to revolutionize how we approach data analysis in diverse fields. This paper not only contributes to the academic discourse on data analysis but also paves the way for practical applications that can leverage these advancements to achieve more accurate and efficient results.
The integration of deep learning models and innovative analytical frameworks marks a significant step forward in the field of text and data analysis. As data grows in volume and complexity, methods like the one proposed in this research will be crucial in ensuring that we can keep pace with information processing and extraction demands.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.










