
NVIDIA Releases Nemotron-Cascade 2: An Open 30B MoE with 3B Active Parameters, Delivering Better Reasoning and Strong Agentic Capabilities

NVIDIA has announced the release of Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts (MoE) model with 3B activated parameters. The model focuses on maximizing ‘intelligence density,’ delivering advanced reasoning capabilities at a fraction of the parameter scale used by frontier models. Nemotron-Cascade 2 is the second open-weight LLM to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals.
Targeted Performance and Strategic Trade-offs
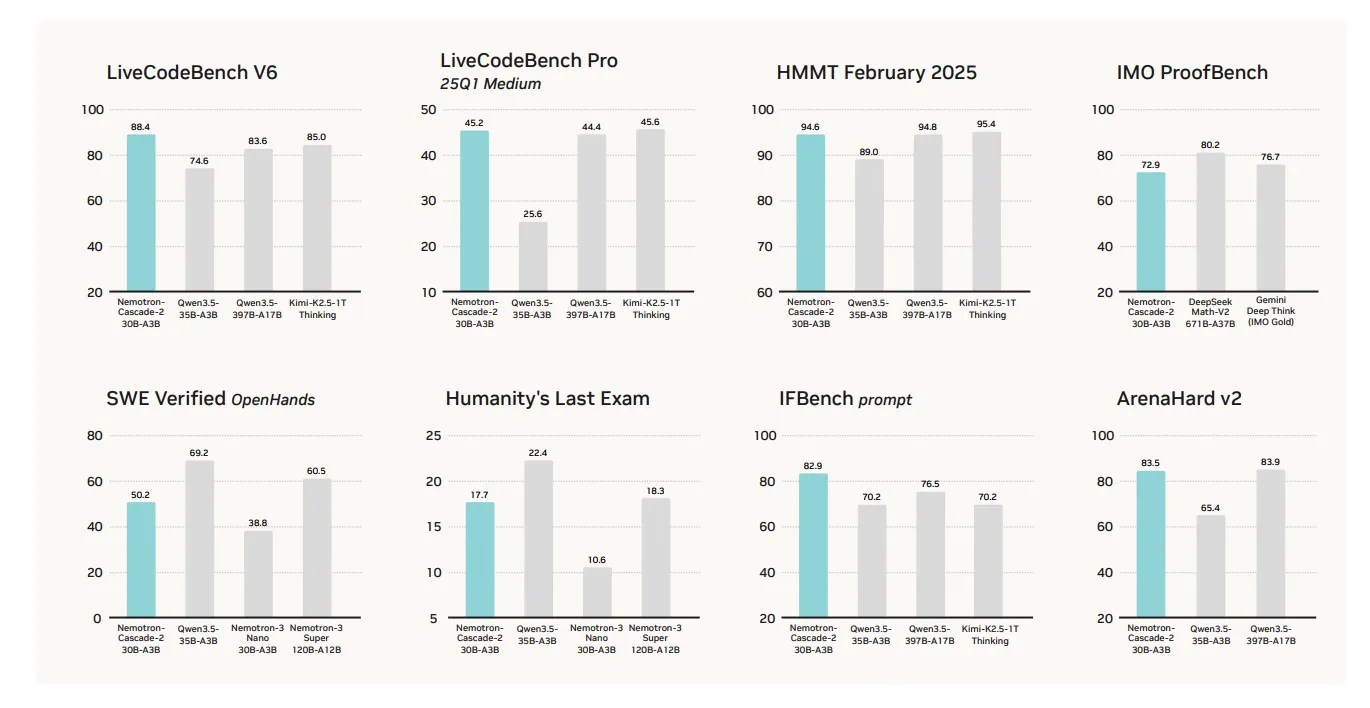
The primary value proposition of Nemotron-Cascade 2 is its specialized performance in mathematical reasoning, coding, alignment, and instruction following. While it achieves state-of-the-art results in these key reasoning-intensive domains, it is surely not a ‘blanket win’ across all benchmarks.
The model’s performance excels in several targeted categories compared to the recently released Qwen3.5-35B-A3B (February 2026) and the larger Nemotron-3-Super-120B-A12B:
Mathematical Reasoning: Outperforms Qwen3.5-35B-A3B on AIME 2025 (92.4 vs. 91.9) and HMMT Feb25 (94.6 vs. 89.0).

Coding: Leads on LiveCodeBench v6 (87.2 vs. 74.6) and IOI 2025 (439.28 vs. 348.6+).
Alignment and Instruction Following: Scores significantly higher on ArenaHard v2 (83.5 vs. 65.4+) and IFBench (82.9 vs. 70.2).
Technical Architecture: Cascade RL and Multi-domain On-Policy Distillation (MOPD)
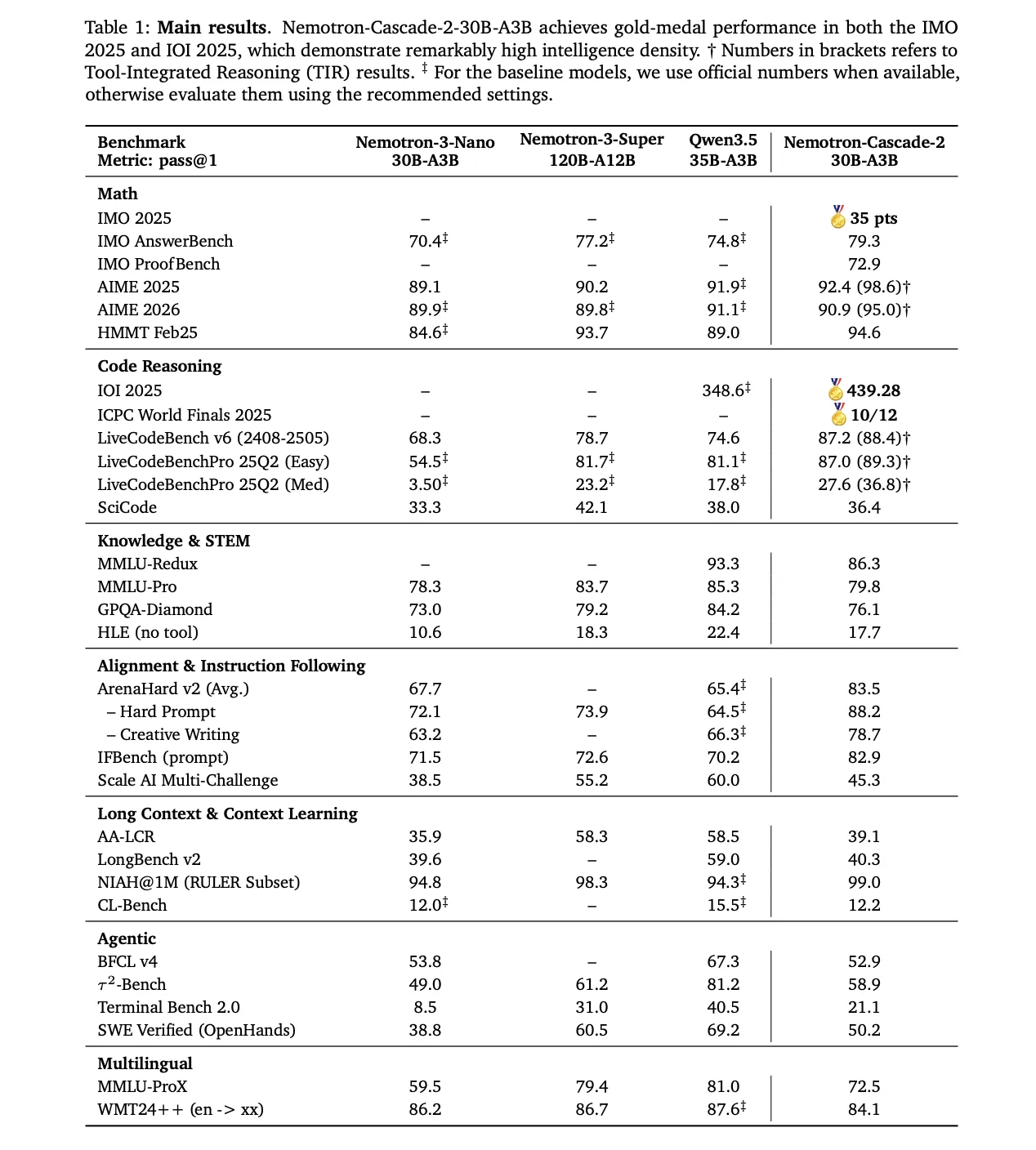
The model’s reasoning capabilities stem from its post-training pipeline, starting from the Nemotron-3-Nano-30B-A3B-Base model.
1. Supervised Fine-Tuning (SFT)
During SFT, NVIDIA research team utilized a meticulously curated dataset where samples were packed into sequences of up to 256K tokens. The dataset included:
1.9M Python reasoning traces and 1.3M Python tool-calling samples for competitive coding.
816K samples for mathematical natural language proofs.
A specialized Software Engineering (SWE) blend consisting of 125K agentic and 389K agentless samples.
2. Cascade Reinforcement Learning
Following SFT, the model underwent Cascade RL, which applies sequential, domain-wise training. This prevents catastrophic forgetting by allowing hyperparameters to be tailored to specific domains without destabilizing others. The pipeline includes stages for instruction-following (IF-RL), multi-domain RL, RLHF, long-context RL, and specialized Code and SWE RL.
3. Multi-Domain On-Policy Distillation (MOPD)
A critical innovation in Nemotron-Cascade 2 is the integration of MOPD during the Cascade RL process. MOPD assembly uses the best-performing intermediate ‘teacher’ models—already derived from the same SFT initialization—to provide a dense token-level distillation advantage. This advantage is defined mathematically as:
$$a_{t}^{MOPD}=log~\pi^{domain_{t}}(y_{t}|s_{t})-log~\pi^{train}(y_{t}|s_{t})$$
The research team found that MOPD is substantially more sample-efficient than sequence-level reward algorithms like Group Relative Policy Optimization (GRPO). For instance, on AIME25, MOPD reached teacher-level performance (92.0) within 30 steps, while GRPO achieved only 91.0 after matching those steps.
Inference Features and Agentic Interaction
Nemotron-Cascade 2 supports two primary operating modes through its chat template:
Thinking Mode: Initiated by a single <think> token, followed by a newline. This activates deep reasoning for complex math and code tasks.
Non-Thinking Mode: Activated by prepending an empty <think></think> block for more efficient, direct responses.
For agentic tasks, the model utilizes a structured tool-calling protocol within the system prompt. Available tools are listed within <tools> tags, and the model is instructed to perform tool calls wrapped in <tool_call> tags to ensure verifiable execution feedback.
By focusing on ‘intelligence density,’ Nemotron-Cascade 2 demonstrates that specialized reasoning capabilities once thought to be the exclusive domain of frontier-scale models are achievable at a 30B scale through domain-specific reinforcement learning.
Check out Paper and Model on HF. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.










